Show the code
['emma', 'olivia', 'ava', 'isabella', 'sophia', 'charlotte', 'mia', 'amelia', 'harper', 'evelyn']
32033This is my study notes / codes along with Andrej Karpathy’s “Neural Networks: Zero to Hero” series.
makemoretakes one text file as input, where each line is assumed to be one training thing, and generates more things like it. Under the hood, it is an autoregressive character-level language model, with a wide choice of models from bigrams all the way to a Transformer (exactly as seen in GPT).
['emma', 'olivia', 'ava', 'isabella', 'sophia', 'charlotte', 'mia', 'amelia', 'harper', 'evelyn']
32033No of chars for the shortest word: 2
No of chars for the longest word: 15By looking into (1) the order of characters in individual word, and (2) that pattern for the whole dataset of 32k words, we will try to infer which character is likely to follow a character or chain of characters.
We will first building a bigrams languague model - which only works will 2 characters at a time - look at the current character and try to predict the next one. We are just following this local structure!
It’s just a simple (and weak) model but a good way to start.
bigrams in the datasetbigrams in a python dictionaryIn order to learn statistics about what character is more likely to follow another character, the simplest way is counting.
[(('a', '<E>'), 5),
(('i', 'a'), 2),
(('<S>', 'e'), 1),
(('e', 'm'), 1),
(('m', 'm'), 1),
(('m', 'a'), 1),
(('<S>', 'o'), 1),
(('o', 'l'), 1),
(('l', 'i'), 1),
(('i', 'v'), 1),
(('v', 'i'), 1),
(('<S>', 'a'), 1),
(('a', 'v'), 1),
(('v', 'a'), 1),
(('<S>', 'i'), 1),
(('i', 's'), 1),
(('s', 'a'), 1),
(('a', 'b'), 1),
(('b', 'e'), 1),
(('e', 'l'), 1),
(('l', 'l'), 1),
(('l', 'a'), 1),
(('<S>', 's'), 1),
(('s', 'o'), 1),
(('o', 'p'), 1),
(('p', 'h'), 1),
(('h', 'i'), 1)]bigrams in a 2D torch tensor (“training the model”)Instead of using Python dictionary, we will use torch 2D array to store this information.
tensor([[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]], dtype=torch.int32)How can we access/assign a value in torch array:
tensor([[ 0, 0, 0, 0, 0],
[10, 10, 10, 10, 10],
[10, 10, 10, 10, 10]], dtype=torch.int32)Now the english alphabet contain 26 characters, we will need to capture the <S> and <E> also. So it would be 28 x 28 array.
This will collect all the characters used in our dataset (join all words to a massive string and pass it to a set(), which will remove duplicate). With such a large dataset, all the english characters were used.
{'a': 0,
'b': 1,
'c': 2,
'd': 3,
'e': 4,
'f': 5,
'g': 6,
'h': 7,
'i': 8,
'j': 9,
'k': 10,
'l': 11,
'm': 12,
'n': 13,
'o': 14,
'p': 15,
'q': 16,
'r': 17,
's': 18,
't': 19,
'u': 20,
'v': 21,
'w': 22,
'x': 23,
'y': 24,
'z': 25,
'<S>': 26,
'<E>': 27}bigram tensorimport matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(16,16))
plt.imshow(N, cmap='Blues')
for i in range(28):
for j in range(28):
# plot character strings with number of time
chstr = itos[i] + itos[j]
plt.text(j, i, chstr, ha="center", va="bottom", color="gray")
plt.text(j, i, N[i, j].item(), ha="center", va="top", color="gray")
plt.axis('off')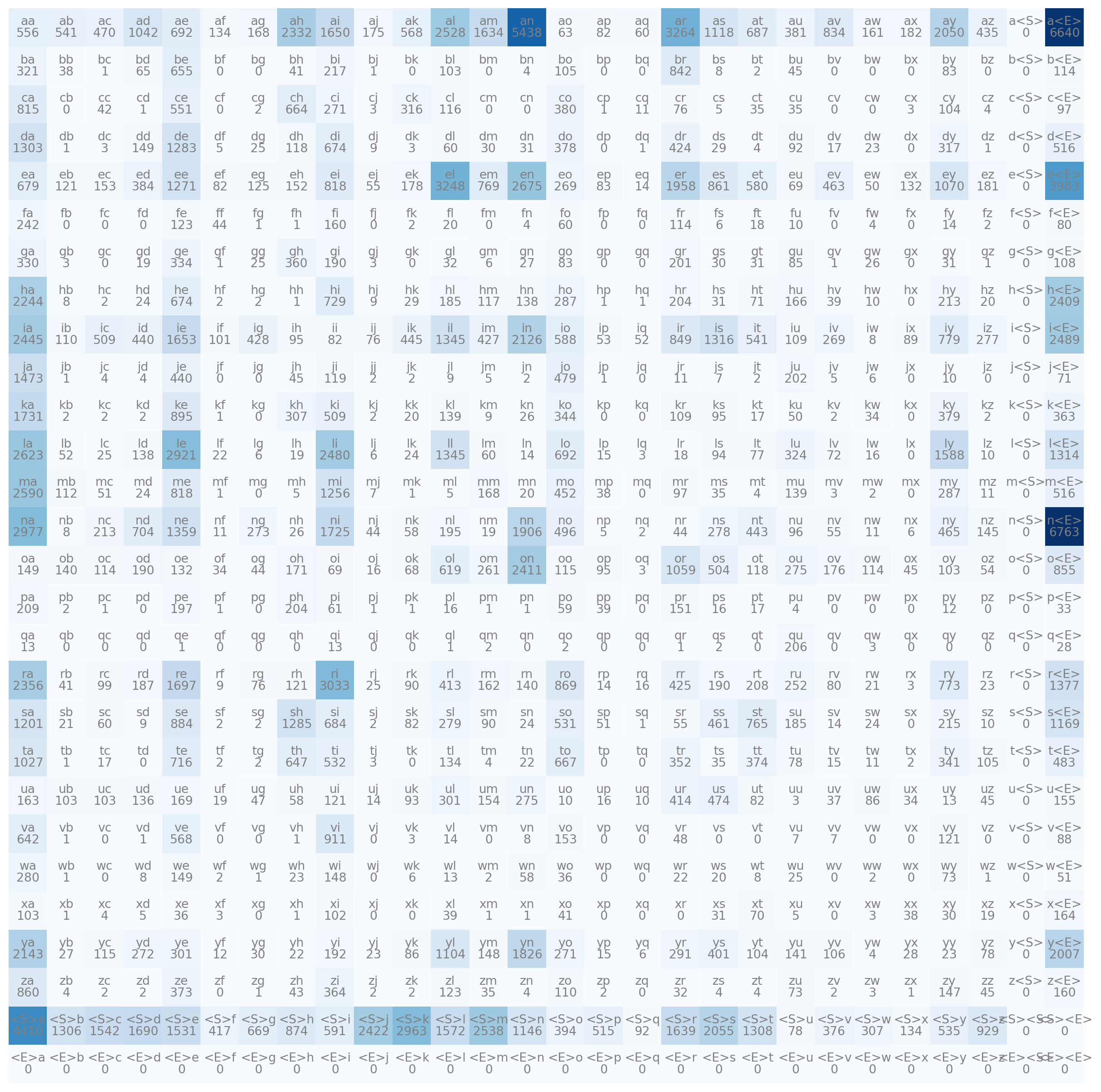
. token<S>, and <E> look a bit annoying. let’s replace them by simple ..
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(16,16))
plt.imshow(N, cmap='Blues')
for i in range(27):
for j in range(27):
chstr = itos[i] + itos[j]
plt.text(j, i, chstr, ha="center", va="bottom", color='gray')
plt.text(j, i, N[i, j].item(), ha="center", va="top", color='gray')
plt.axis('off')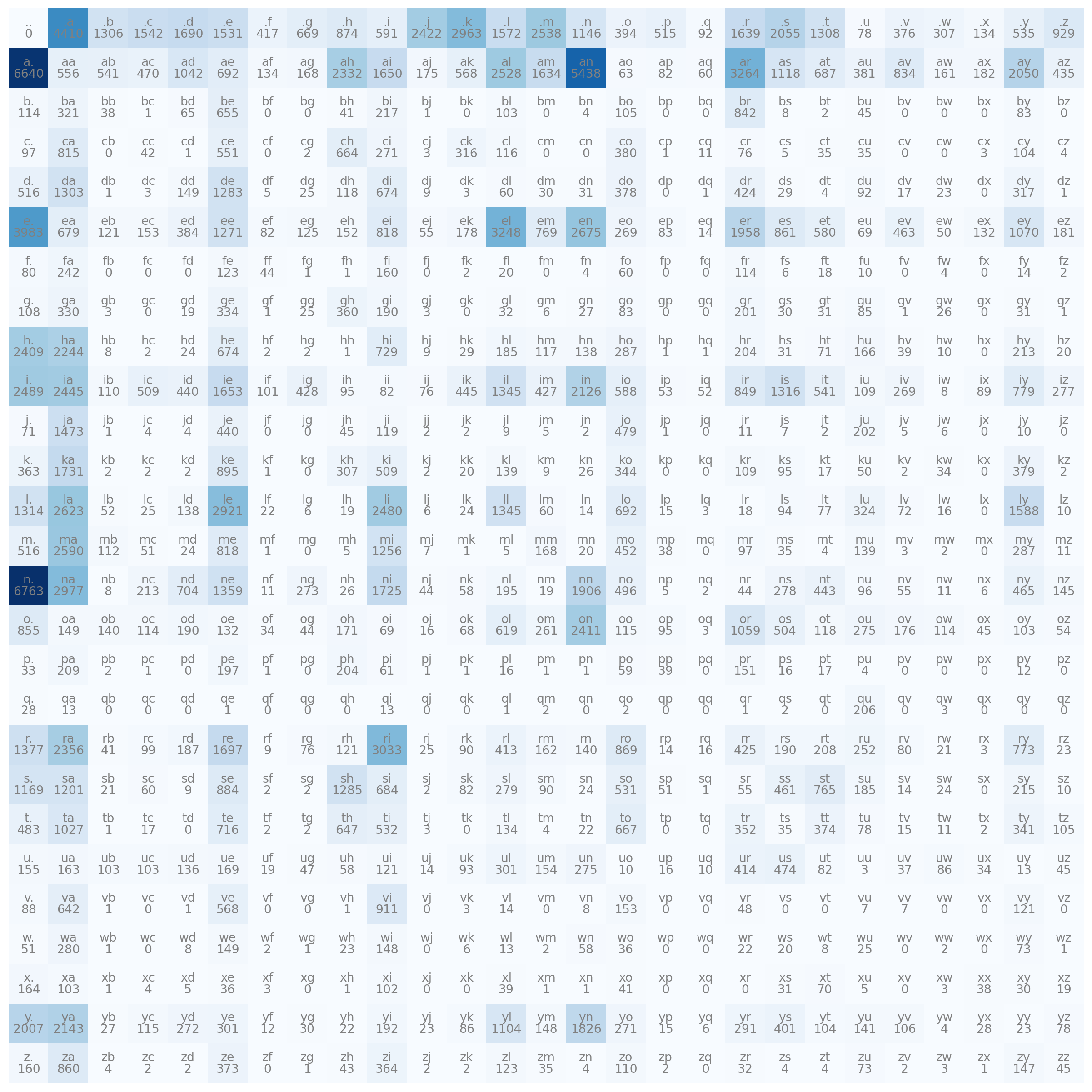
Taking the first column of the array.
tensor([ 0, 4410, 1306, 1542, 1690, 1531, 417, 669, 874, 591, 2422, 2963,
1572, 2538, 1146, 394, 515, 92, 1639, 2055, 1308, 78, 376, 307,
134, 535, 929], dtype=torch.int32)Column-wise probability.
tensor([0.0000, 0.1377, 0.0408, 0.0481, 0.0528, 0.0478, 0.0130, 0.0209, 0.0273,
0.0184, 0.0756, 0.0925, 0.0491, 0.0792, 0.0358, 0.0123, 0.0161, 0.0029,
0.0512, 0.0642, 0.0408, 0.0024, 0.0117, 0.0096, 0.0042, 0.0167, 0.0290])Creating random number with Pytorch generator at a state.
tensor([1, 1, 2, 0, 0, 2, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 2, 0, 0,
1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1,
0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 1, 0, 0, 2, 0, 1, 0,
0, 1, 1, 1])Now back to our data, generate a tensor with 1 value from the p vector.
'j'Let’s automate it:
j
u
n
i
d
e
.And more, joining the last result to single word, and make new 10 names:
g = torch.Generator().manual_seed(2147483647)
for i in range(10):
out = []
ix = 0
while True:
p = N[ix].float()
p = p / p.sum()
# p = torch.ones(27) / 27.0
# the result look terrible, but compare to an un-trained model for eg p - uncomment to code above, they are still like names.
ix = torch.multinomial(p, num_samples=1, replacement=True, generator=g).item()
out.append(itos[ix])
if ix == 0:
break
print(''.join(out))junide.
janasah.
p.
cony.
a.
nn.
kohin.
tolian.
juee.
ksahnaauranilevias.We just fetching a row of N from the counts matrix, and then always do the same things: converting to float, dividing. That’s not efficient! We now will optimize this:
P = N.float()
# param 1 helps summing horizontally, by rows
# keepdim keeps the dimension the output is still 2D array with 1 column for each row, not a vertical vector entirely
# tensor already support to broadcast the row sum allowing this dividing (keepdim helped not to mess the broadcast)
P /= P.sum(1, keepdim=True)
# inplace operator instead of P = P / P.sum(1, keepdim=True), take care of memory!junide.
janasah.
p.
cony.
a.
nn.
kohin.
tolian.
juee.
ksahnaauranilevias.We’ve just trained and sampled from the model, iteratively sampled the next character and fed it in each time and got the next one. Now we need to somehow measure the quality of the model.
How good is it in predicting? Gimme a number!
# showing bigram for the first 3 words, along with the probability inferred by our model (`P`)
# the higher the prob, the better of prediction
# since a fair (under no data) probability of occuring a character is roughly 1/27 ~ 4%, any prob higher than 4% should be good
# we need to combine all the prob to a single 1 number, measuring how good is our model?
# since multiplying all the prob resulting a very very small number, we will approach by the log likelihood function
# the log likelihood is just the sum of log of individual multiplier
log_likelihood = 0.0
for w in words[:3]:
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
ix1 = stoi[ch1]
ix2 = stoi[ch2]
prob = P[ix1, ix2]
log_prob = torch.log(prob)
log_likelihood += log_prob
print(f'{ch1}{ch2}: {prob:.4f} {log_prob:.4f}')
print(f'{log_likelihood=}') # print both the variable name and its value, for the first 3 words.e: 0.0478 -3.0408
em: 0.0377 -3.2793
mm: 0.0253 -3.6772
ma: 0.3899 -0.9418
a.: 0.1960 -1.6299
.o: 0.0123 -4.3982
ol: 0.0780 -2.5508
li: 0.1777 -1.7278
iv: 0.0152 -4.1867
vi: 0.3541 -1.0383
ia: 0.1381 -1.9796
a.: 0.1960 -1.6299
.a: 0.1377 -1.9829
av: 0.0246 -3.7045
va: 0.2495 -1.3882
a.: 0.1960 -1.6299
log_likelihood=tensor(-38.7856)If all the probs equal to 1, the logs will be 0. If they close to 0, the logs will be more negative. We want to use this as a loss function, meaning lower the better, so we will invert it:
neg_log_likelihood=tensor(559891.7500)
2.454094171524048Finally we insert a count and calculate the “normalized” (or average) negative log likelihood. The lower of this number, the better model we have.
You can test with your name:
neg_log_likelihood = 0.0
n = 0
for w in ['tuan']:
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
ix1 = stoi[ch1]
ix2 = stoi[ch2]
prob = P[ix1, ix2]
log_prob = torch.log(prob)
neg_log_likelihood += -log_prob
n += 1
print(f'{ch1}{ch2}: {prob:.4f} {log_prob:.4f}')
print(f'{neg_log_likelihood=}')
print(f'{neg_log_likelihood/n}').t: 0.0408 -3.1983
tu: 0.0140 -4.2684
ua: 0.0520 -2.9566
an: 0.1605 -1.8296
n.: 0.3690 -0.9969
neg_log_likelihood=tensor(13.2498)
2.649962902069092tu is not common in our dataset.
For a pair of bigram that does not exist in the dataset, for eg jq, the prob will be zero and log likelihood will be infinity. We can kind of smooth our model by adding constant “fake counts” to the model:
1 is decent number, the more you added, you’ll have a more uniformed distribution, the less, the more peaked distribution you have.
Now we will try to cast the problem of bigram character level of language modeling into the neural network framework. We first understand how to feed it in with 1 point dataset - only the first word emma:
bigram dataset for the neural net# creating training set of bigram(x, y)
xs, ys = [], []
for w in words[:1]:
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
ix1 = stoi[ch1]
ix2 = stoi[ch2]
xs.append(ix1)
ys.append(ix2)
xs = torch.tensor(xs) # both .tensor() and .Tensor() work!
ys = torch.tensor(ys)
# https://stackoverflow.com/questions/51911749/what-is-the-difference-between-torch-tensor-and-torch-tensor
# .tensor() infers dtype as int64 while .Tensor() infers dtype as float32, in this caseThe input and output tensor for the first word will be look like this:
tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.]])tensor([[-2.2498],
[ 2.3020],
[-0.3719],
[-0.3719],
[-0.3827]])This is 1 neuron only, now we want to evaluate all 27 characters using only 5 inputs from the first word, we’ll make 27 neurons:
tensor([[-0.0355, 2.3155, 0.2896, 1.6266, -0.0783, -0.7462, -1.2353, -0.0841,
-0.2500, 0.1591, -1.1639, 0.4458, 1.1365, 0.9159, 1.0602, -0.9488,
-1.1932, 0.3338, 0.0301, -0.2639, 0.5924, -1.0144, -2.3080, -0.7702,
0.3844, 1.6278, 0.9473],
[-0.2300, 0.8866, -0.4229, 1.2298, 2.0847, 0.6033, -1.0144, -1.5902,
1.0441, -0.4558, -1.1732, 0.0468, 1.3476, -1.2999, 0.4707, -0.9575,
-0.5092, 0.7076, -1.1781, 0.8005, 0.7489, 1.9017, -0.3109, -1.2747,
-1.1256, 0.0907, -0.0929],
[ 0.3460, -0.3902, -2.1835, 0.0527, -1.0908, 1.4131, -1.0061, -2.4889,
-0.0110, 0.1494, -0.5154, 1.0459, -0.1377, -1.1176, -0.1330, 1.4926,
1.7071, -1.1803, 1.0755, 1.2720, -1.0548, 0.2015, -0.2355, 1.5274,
0.4777, 0.8109, 1.1829],
[ 0.3460, -0.3902, -2.1835, 0.0527, -1.0908, 1.4131, -1.0061, -2.4889,
-0.0110, 0.1494, -0.5154, 1.0459, -0.1377, -1.1176, -0.1330, 1.4926,
1.7071, -1.1803, 1.0755, 1.2720, -1.0548, 0.2015, -0.2355, 1.5274,
0.4777, 0.8109, 1.1829],
[-0.5041, 2.1254, -1.9396, -0.7349, 1.1386, 0.6593, -0.5744, -0.9488,
-0.5028, 1.0566, -0.2909, 0.7718, -0.2889, -0.6343, -1.3896, -0.0291,
-1.4302, -1.4050, 0.5104, 1.2061, 0.9506, -2.0897, -1.0904, -0.2561,
-0.5369, 0.8944, 0.9525]])So far we have fed 5 inputs to 27 neurons for 27 characters in the first layer of the neural net. We notice that the output number ranges from negative to positive while we want “how likely of the next characters”. It would be counts, or probs, hence we exponentiate the logits, then dividing row-wise total to get the prob of each character.
This is call the softmax!
tensor([[0.0200, 0.2101, 0.0277, 0.1055, 0.0192, 0.0098, 0.0060, 0.0191, 0.0162,
0.0243, 0.0065, 0.0324, 0.0646, 0.0518, 0.0599, 0.0080, 0.0063, 0.0290,
0.0214, 0.0159, 0.0375, 0.0075, 0.0021, 0.0096, 0.0305, 0.1056, 0.0535],
[0.0173, 0.0528, 0.0142, 0.0744, 0.1749, 0.0397, 0.0079, 0.0044, 0.0618,
0.0138, 0.0067, 0.0228, 0.0837, 0.0059, 0.0348, 0.0083, 0.0131, 0.0441,
0.0067, 0.0484, 0.0460, 0.1456, 0.0159, 0.0061, 0.0071, 0.0238, 0.0198],
[0.0303, 0.0145, 0.0024, 0.0226, 0.0072, 0.0880, 0.0078, 0.0018, 0.0212,
0.0249, 0.0128, 0.0610, 0.0187, 0.0070, 0.0188, 0.0953, 0.1181, 0.0066,
0.0628, 0.0764, 0.0075, 0.0262, 0.0169, 0.0987, 0.0345, 0.0482, 0.0699],
[0.0303, 0.0145, 0.0024, 0.0226, 0.0072, 0.0880, 0.0078, 0.0018, 0.0212,
0.0249, 0.0128, 0.0610, 0.0187, 0.0070, 0.0188, 0.0953, 0.1181, 0.0066,
0.0628, 0.0764, 0.0075, 0.0262, 0.0169, 0.0987, 0.0345, 0.0482, 0.0699],
[0.0153, 0.2124, 0.0036, 0.0122, 0.0792, 0.0490, 0.0143, 0.0098, 0.0153,
0.0729, 0.0190, 0.0549, 0.0190, 0.0134, 0.0063, 0.0246, 0.0061, 0.0062,
0.0422, 0.0847, 0.0656, 0.0031, 0.0085, 0.0196, 0.0148, 0.0620, 0.0657]])micrograd# randomly initialize 27 neurons' weights. each neuron receives 27 inputs
g = torch.Generator().manual_seed(2147483647) # to make sure we all have same random
W = torch.randn((27, 27), generator=g)
xenc = F.one_hot(xs, num_classes=27).float() # input to the network: one-hot encoding
logits = xenc @ W # predict log-counts
counts = logits.exp() # counts, equivalent to N
probs = counts / counts.sum(1, keepdims=True) # probabilities for next character
# btw: the last 2 lines here are together called a 'softmax'Below is detail explaination for each example from our 5-datapoint dataset.
nlls = torch.zeros(5)
for i in range(5):
# i-th bigram:
x = xs[i].item() # input character index
y = ys[i].item() # label character index
print('--------')
print(f'bigram example {i+1}: {itos[x]}{itos[y]} (indexes {x},{y})')
print('input to the neural net:', x)
print('output probabilities from the neural net:', probs[i])
print('label (actual next character):', y)
p = probs[i, y]
print('probability assigned by the net to the the correct character:', p.item())
logp = torch.log(p)
print('log likelihood:', logp.item())
nll = -logp
print('negative log likelihood:', nll.item())
nlls[i] = nll
print('=========')
print('average negative log likelihood, i.e. loss =', nlls.mean().item())--------
bigram example 1: .e (indexes 0,5)
input to the neural net: 0
output probabilities from the neural net: tensor([0.0200, 0.2101, 0.0277, 0.1055, 0.0192, 0.0098, 0.0060, 0.0191, 0.0162,
0.0243, 0.0065, 0.0324, 0.0646, 0.0518, 0.0599, 0.0080, 0.0063, 0.0290,
0.0214, 0.0159, 0.0375, 0.0075, 0.0021, 0.0096, 0.0305, 0.1056, 0.0535])
label (actual next character): 5
probability assigned by the net to the the correct character: 0.009835068136453629
log likelihood: -4.621800899505615
negative log likelihood: 4.621800899505615
--------
bigram example 2: em (indexes 5,13)
input to the neural net: 5
output probabilities from the neural net: tensor([0.0173, 0.0528, 0.0142, 0.0744, 0.1749, 0.0397, 0.0079, 0.0044, 0.0618,
0.0138, 0.0067, 0.0228, 0.0837, 0.0059, 0.0348, 0.0083, 0.0131, 0.0441,
0.0067, 0.0484, 0.0460, 0.1456, 0.0159, 0.0061, 0.0071, 0.0238, 0.0198])
label (actual next character): 13
probability assigned by the net to the the correct character: 0.00592648284509778
log likelihood: -5.128324508666992
negative log likelihood: 5.128324508666992
--------
bigram example 3: mm (indexes 13,13)
input to the neural net: 13
output probabilities from the neural net: tensor([0.0303, 0.0145, 0.0024, 0.0226, 0.0072, 0.0880, 0.0078, 0.0018, 0.0212,
0.0249, 0.0128, 0.0610, 0.0187, 0.0070, 0.0188, 0.0953, 0.1181, 0.0066,
0.0628, 0.0764, 0.0075, 0.0262, 0.0169, 0.0987, 0.0345, 0.0482, 0.0699])
label (actual next character): 13
probability assigned by the net to the the correct character: 0.007006798405200243
log likelihood: -4.960874557495117
negative log likelihood: 4.960874557495117
--------
bigram example 4: ma (indexes 13,1)
input to the neural net: 13
output probabilities from the neural net: tensor([0.0303, 0.0145, 0.0024, 0.0226, 0.0072, 0.0880, 0.0078, 0.0018, 0.0212,
0.0249, 0.0128, 0.0610, 0.0187, 0.0070, 0.0188, 0.0953, 0.1181, 0.0066,
0.0628, 0.0764, 0.0075, 0.0262, 0.0169, 0.0987, 0.0345, 0.0482, 0.0699])
label (actual next character): 1
probability assigned by the net to the the correct character: 0.014500692486763
log likelihood: -4.233558654785156
negative log likelihood: 4.233558654785156
--------
bigram example 5: a. (indexes 1,0)
input to the neural net: 1
output probabilities from the neural net: tensor([0.0153, 0.2124, 0.0036, 0.0122, 0.0792, 0.0490, 0.0143, 0.0098, 0.0153,
0.0729, 0.0190, 0.0549, 0.0190, 0.0134, 0.0063, 0.0246, 0.0061, 0.0062,
0.0422, 0.0847, 0.0656, 0.0031, 0.0085, 0.0196, 0.0148, 0.0620, 0.0657])
label (actual next character): 0
probability assigned by the net to the the correct character: 0.015316599979996681
log likelihood: -4.178818225860596
negative log likelihood: 4.178818225860596
=========
average negative log likelihood, i.e. loss = 4.624675273895264# create the dataset
xs, ys = [], []
for w in words:
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
ix1 = stoi[ch1]
ix2 = stoi[ch2]
xs.append(ix1)
ys.append(ix2)
xs = torch.tensor(xs)
ys = torch.tensor(ys)
num = xs.nelement()
print('number of examples: ', num)
# initialize the 'network'
g = torch.Generator().manual_seed(2147483647)
W = torch.randn((27, 27), generator=g, requires_grad=True)number of examples: 228146# gradient descent
for k in range(1): # after run 100 times, shorten the notebook
# forward pass
xenc = F.one_hot(xs, num_classes=27).float() # input to the network: one-hot encoding
logits = xenc @ W # predict log-counts
counts = logits.exp() # counts, equivalent to N
probs = counts / counts.sum(1, keepdims=True) # probabilities for next character
loss = -probs[torch.arange(num), ys].log().mean() + 0.01*(W**2).mean() # regularization loss
print(loss.item())
# backward pass
W.grad = None # set to zero the gradient
loss.backward()
# update
W.data += -50 * W.grad3.768618583679199Looking back to the backprogation in the lesson 1, everything look similar here:
| Part | This neural nets for bigram language modeling | Neural nets introduced in the lesson 1 |
|---|---|---|
| Forward pass | probs , use negative log likelihood as loss function, doing classification |
ypred , use MSE for loss function, doing regression |
| Backward pass | Same, offered by Torch. | Set grad of params to be zeros and do backpropagation. |
| Update loss | Same | Update the parameters, change the parameters following opposite direction to reduce the loss. |
Look at the below code, xenc @ W is (5, 27) @ (27, 27) that will result (5, 27) matrix. Each ix row of that 5-rows result matrix should be the selection of corresponding character rows in the W.
So in this gradient-based framework, we start with a random array of parameters. By optimizing the loss function we will get the same result with the bigram approach (W and N are almost the same, it’s log count here why is count in bigram). That’s why we obtained the same loss!
The neural networks offer more flexibility!
Same with smoothing technique when we’ve doing the bigram model, gradient-based framework have an equivalent way for smoothing. We will try to incentivize W to be near zero. We augment to loss function by adding this: 0.01*(W**2).mean().
# finally, sample from the 'neural net' model
g = torch.Generator().manual_seed(2147483647)
for i in range(5):
out = []
ix = 0
while True:
# ----------
# BEFORE:
# p = P[ix]
# ----------
# NOW:
xenc = F.one_hot(torch.tensor([ix]), num_classes=27).float()
logits = xenc @ W # predict log-counts
counts = logits.exp() # counts, equivalent to N
p = counts / counts.sum(1, keepdims=True) # probabilities for next character
# ----------
ix = torch.multinomial(p, num_samples=1, replacement=True, generator=g).item()
out.append(itos[ix])
if ix == 0:
break
print(''.join(out))juwjdjdjancqydjufhqyywecnw.
.
oiin.
toziasz.
twt.What we’ve gone through:
We are on the way out to transformer!
Thank you, Andrej!
makemore Github repo: https://github.com/karpathy/makemore